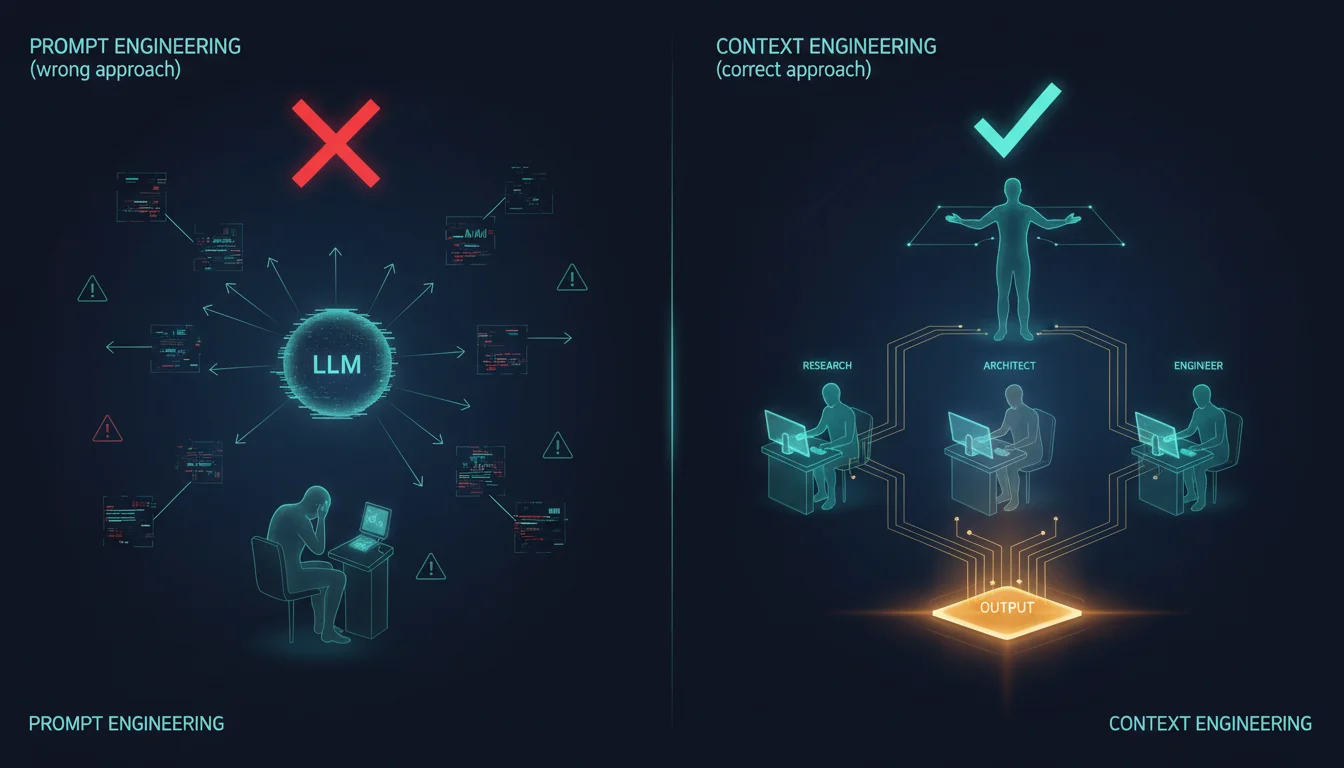
Most teams trying to get more out of AI are asking the wrong question. They want better prompts when what they actually need is better architecture — a system that decides what each agent knows, when it knows it, and how information flows between agents across a workflow.
The Ceiling That Prompt Engineering Can't Clear
Prompt engineering treats an LLM interaction as a tuning problem. You have a system prompt, a user message, and a response — and you iterate on the wording until the model produces what you want. It works well for demos, for single-turn interactions, for assistant applications where a user types questions and reads answers. But production AI isn't a chatbot. It's a workflow.
When you try to scale a well-prompted LLM into a system that completes multi-step work — generating a product spec, implementing a feature, reviewing code, updating documentation — you run into a ceiling that prompt engineering cannot help you clear. The problem isn't the wording of your instructions. The problem is that a single LLM can't hold the entire context of a complex workflow without losing precision. You're trying to do architectural work with a text editor.
The failure mode is predictable: the model starts making confident decisions in one part of the task that contradict decisions it made ten steps earlier, because those earlier decisions have drifted out of its active attention. More detailed prompts don't fix this. More tokens in the system prompt don't fix this. The context window is a budget, and you're spending it all on a single agent that's trying to do everything.
Context Engineering Is Systems Design
Context engineering is the discipline of deciding what each agent knows, when it knows it, and how knowledge accumulates across a workflow. But before we frame it as an AI concept, it's worth noting what it actually is: a human organizational principle that high-functioning teams have practiced for decades.
Think about how a capable development team solves a large problem. The architect owns the system design — they hold the structural decisions and constraints that everyone else must work within. The frontend engineer owns the UI layer; they don't need to understand the database migration strategy to write a great component. The QA lead owns the validation criteria; they don't need to know why a particular API endpoint was designed the way it was to verify that it behaves correctly. Each discipline carries deep context within its vertical and receives only the cross-cutting context it needs from other verticals. That's not a limitation — it's precisely what makes teams capable of tackling work that no single person could hold in their head.
Enterprise organizations scale this further. A business process team running a major operational workflow doesn't hand every document and decision to every participant. They design information flows: who gets briefed on what, at what stage, with what framing for their role. The team lead holds strategic context. The specialists execute within well-scoped domains. Shared artifacts — a brief, a spec, a handoff document — carry knowledge from one discipline to the next without requiring every participant to rediscover what the previous one already established. The system as a whole completes work that none of its parts could manage alone.
Context engineering in agentic AI is the same design problem applied to the same challenge. We built Zoe, our AI orchestration layer, around this principle — and we treat the context window exactly the way a finance team treats a budget: every allocation is intentional, every category has a ceiling, and the most important rule is that the person responsible for the whole doesn't spend resources meant for the people doing the work.
Zoe's context budget runs like this against a 100% context window:
- Orchestrator reserve — 30–40%: held for strategic oversight, synthesizing agent outputs, and interacting with the user. This never gets spent on execution work.
- Agent summaries — 20–30%: accumulated results from completed agents. As work finishes, the orchestrator retains structured summaries — what was done, what was decided, what files were changed — not the full output.
- Current task — 20–30%: the active agent's working context. The specialist gets what it needs; the orchestrator doesn't carry this weight.
- Overflow buffer — 10%: reserved for unexpected scope, clarification loops, or edge cases that appear mid-workflow.
When a task would consume more than 5% of the orchestrator's reserve — reading code, writing implementations, running build commands — Zoe delegates it to a specialist. The orchestrator stays at the strategic level, holding sequencing, dependencies, and cross-cutting decisions, just as a team lead does when execution work is running in parallel below them. The budget model isn't a constraint on what Zoe can do — it's what makes Zoe capable of managing complex, multi-stage work without losing coherence as the workflow grows.
Zoe also implements a Skill-First Protocol: before any session begins doing ad hoc work, it checks whether a skill — a workflow program encoding how to handle a class of tasks — already exists for what's being asked. This is context engineering at the meta level. The skill doesn't just describe what to do; it encodes the information routing logic that makes it work. Which agents receive which context, in which order, with which framing. That knowledge lives in the skill, not in the session.
Parallel Context Distribution: Same Input, Different Frames
One of the more powerful context engineering patterns is parallel context distribution — giving multiple agents the same raw input but framing the context differently for each one based on its domain.
When Zoe kicks off a new project, the project-ideation skill launches three agents simultaneously. The research-analyst receives a product discovery frame: user personas, key journeys, success metrics, competitive landscape. The technical-analyst receives a feasibility frame: stack compatibility, infrastructure requirements, integration complexity, technical risks. The ux-designer receives a complexity frame: screen inventory, user flows, accessibility targets, mobile platform constraints. Same raw idea from the user. Three distinct context frames. Three specialized outputs that compose into a complete picture.
This is what separates context engineering from prompt engineering. We didn't write a smarter prompt. We designed an information flow. Each agent receives exactly the context that makes it productive in its domain, and nothing that distracts from that domain. The outputs arrive faster than any single agent could produce them — and they're better, because each agent is reasoning from a focused frame rather than a sprawling one.
Phase 2 of that workflow makes the accumulation explicit: the architect agent receives the synthesized outputs from all three — the research analysis, the technical analysis, the UX discovery document. It doesn't rebuild what those agents found. The context has been accumulated, organized, and handed forward. Each phase inherits from the previous one without restarting.
Sequential Context Accumulation: The Compounding Chain
Sequential workflows reveal a different pattern: context that compounds through a chain of agents, each one building on what the previous agent established.
Zoe's dev-workflow skill starts not with implementation but with a context-building pass. Before the sprint-programmer writes a single line of code, a technical-analyst produces a Story Context Block — a structured summary of the current codebase state, relevant file paths, architectural constraints, and infrastructure reality that applies to the story being implemented. This artifact exists for one reason: to prime the sprint-programmer with what it needs to make the right implementation choices on the first pass, rather than discovering architectural realities mid-stream and having to backtrack.
The sprint-context.md file carries that context forward through the entire sprint. It's warm memory — persisted between agent invocations — so every agent in the sprint inherits the decisions of previous agents without having to rediscover them. When the code-reviewer analyzes the implementation, it already knows the architectural constraints that shaped it. When the pre-commit-validator runs, it doesn't need the full design rationale — it only needs the diff and the validation rules.
This last point is critical. The pre-commit-validator receiving the full product reasoning would be waste. It would consume context budget on information that doesn't change what the validator needs to do. Narrow context isn't a limitation on the agent — it's what makes the agent precise. Agent specialization enforced through context scoping is how you turn a chain of agents into a chain of experts rather than a chain of generalists each trying to remember everything.
The Harness Is the Product
Here's the insight most teams miss: the workflows that route context through a multi-agent system aren't infrastructure beneath your AI application. They are the application.
Zoe's orchestration skill, project-ideation skill, and dev-workflow skill aren't prompts that have been refined over time. They're workflow programs — structured specifications of what gets passed to whom, in what order, with what framing, and what gets preserved for downstream agents. When you look at Zoe's MEMORY.md, hot.md, and sprint-context.md files, you're looking at context engineering artifacts: carefully designed injection points that prime agents with exactly the knowledge they need at exactly the moment they need it.
Every one of those design decisions — what to store in warm memory versus cold archive, which agents run in parallel versus sequence, how much context to give the orchestrator versus delegate to specialists — is a context engineering decision. And the quality of your production AI system is determined more by those decisions than by any individual prompt.
The teams that will pull ahead aren't the ones with the cleverest prompts. They're the ones that have stopped treating AI as a chatbot they're prompting and started treating it as a system they're architecting — where the most important engineering decisions concern what each agent knows, when it knows it, and how that knowledge compounds through the workflow.
If you're hitting the ceiling of prompt engineering and want to talk through what a context-engineered architecture would look like for your stack, reach out to us. This is the work we're doing at BrinsCorp, and it's the work we help companies bring to production.



